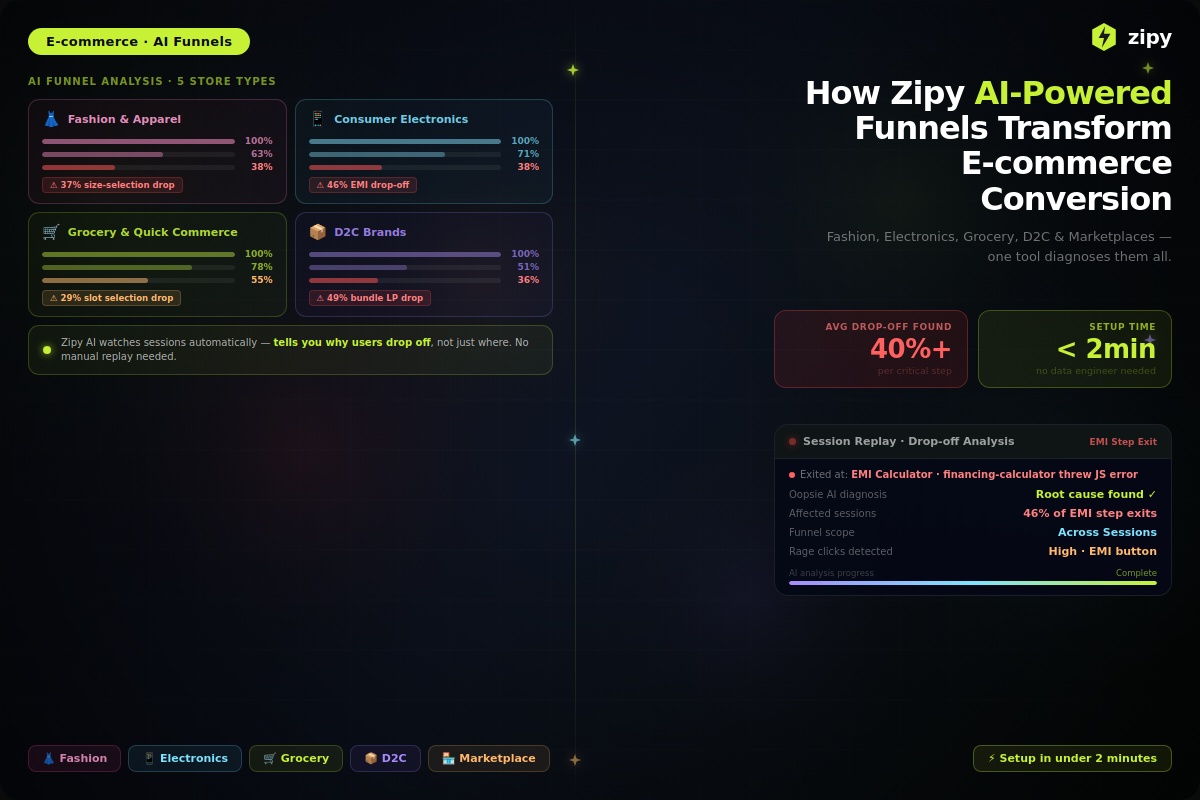
.svg)





In this piece, we will look at what goes behind the browser’s window when we search for any website (domain) in the address bar of the browser. Basically, we will try to understand how the browser converts our designed HTML into web pages.
As a developer, while building a web application it is very important to write the code in such a way that it can run smoothly and effortlessly in any browser. Understanding the internals of browsers helps us in making better decisions during development so that the performance and functionality of the application are at optimum levels.
Let’s first understand, What is a Browser?
In simple words, we all know a browser is an application which is used to access websites and consequently access information that is available on the internet.
Browser’s main functionality
The browser’s primary functionality or task is to display the web resource the user has requested by accessing it from the server and displaying it on the browser’s window.
Here, the web resource is an HTML document which can contain images, PDFs, videos, forms etc.
As of now, there are many browsers which provide us with this functionality and the most popular ones are Chrome, Safari, Firefox, Edge and Internet Explorer.
What happens when you type any URL in the browser address bar?
When you type any URL(Uniform Resource Locator) of any web page in the address bar of your browser, it fetches the document (HTML files containing images, PDF, videos etc.) at that URL from the web server (where our application code resides), interprets it and then renders the content on the browser screen.
Let’s see how this work within the browser with the help of the illustration below:
- The user Enters the URL (say for example https://www.zipy.ai ) in the address bar.
- The first step for the browser is to resolve the domain name (here zipy.ai) and map it to an IP Address. To find the IP address of the domain, the browser first checks all the local DNS caches for the availability of the mapping:
- Browser’s local cache
- Operating System’s cache
- The router’s cache
- Lastly, ISP’s local cache
- If none of them has an entry that matches the domain, then a call is made to the DNS server for resolution.
- If the IP address is not present in the Browser DNS cache then it makes the system call to fetch the IP (OS also maintains the cache of recent DNS queries). If the IP is still not found, then the search continues to the router which has its own cache. If everything fails then DNS lookup comes into the picture, where it finds the IP address from the list of available options like Google.
- Now, if the DNS does not fetch the IP address then it will show the top 10 matching results.
- If an IP address is found, the browser makes the TCP connection to the IP address (server) and sends an HTTP/HTTPS GET request to that IP address with some information which it has gathered (What's the exact URL? Which kind of request should be made? Should metadata be attached?).
Browser now receives the http/https response (response will contain all the code that is required by the browser to render the page onto the screen) and closes the TCP connection and may use it for another request. Now the browser parses the response based on the data and metadata that is enclosed with it. The browser then uses the processed data to form the website content to display on the UI. How does that really work? - we will delve into it in the next section.
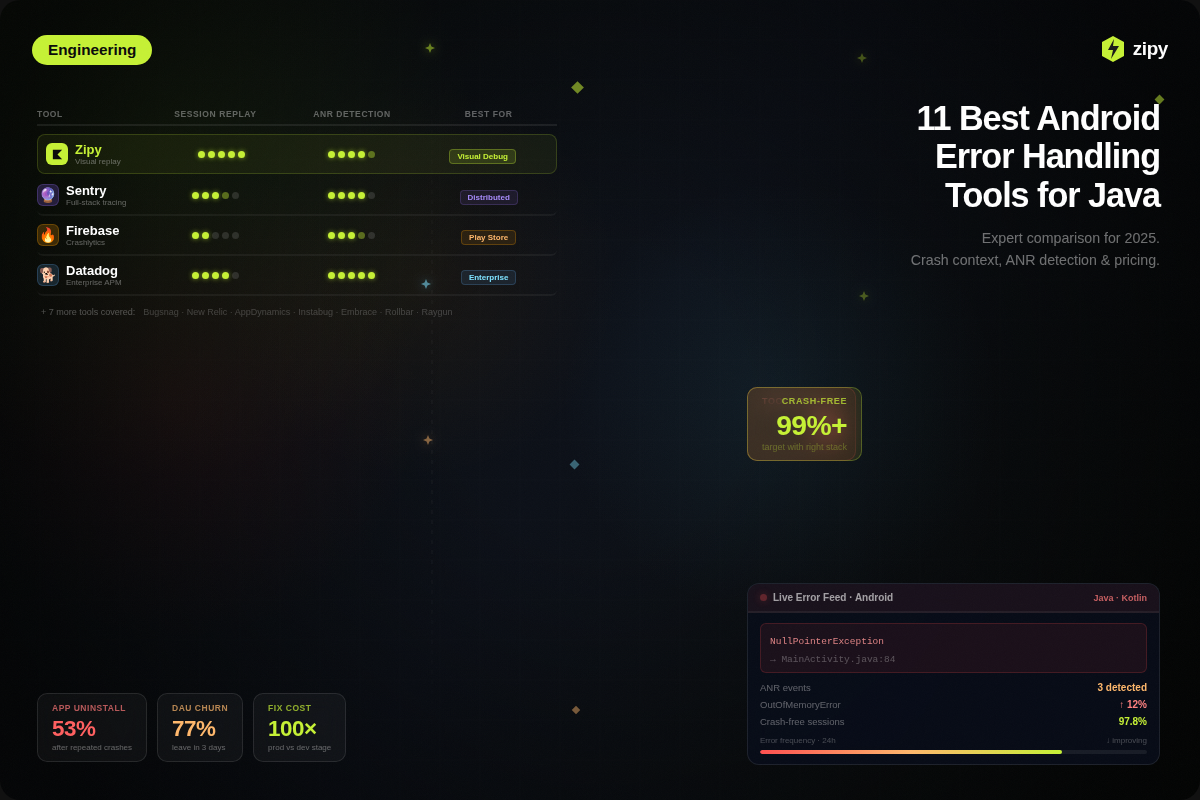
Architecture of the Browser
The browser mainly consists of User Interface, Browser Engine, Rendering Engine, Data Persistence, Networking, JavaScript Interpreter and UI Backend. Below is a hierarchical diagram that shows the different components of a browser.
User Interface
It is a collection of UI components visible on the browser which are consumed by the user for different reasons.
It includes the address bar, back/forwards navigation button and all other elements that fetch and display the web page requested by the end-user - every part of the browser display, except the window where you see the actually requested web pages.
Browser Engine
Each browser has a browser engine under the hood. It works as a bridge between the user interface and the rendering engine. It queries and manipulates the rendering engine based on the input it gets from the user interface.
The browser engine decides when what and how HTML tags, images and CSS need to be arranged/rendered. Basically, all that is seen by the user is processed by the browser engine.
The different browser engines that are used in browsers are:
- WebKit: Safari
- Gecko: Firefox
- Trident: IE
- Presto: Opera
- Blink: Google Chrome and Opera v.15+
All these engines are written in C++.
Rendering Engine
It interprets the HTML and XML documents along with the images that are styled or formatted using CSS, and a final layout is generated, which is displayed on the user interface.
In simple words, it parses the HTML and CSS to display the parsed content on the screen.
This diagram is for Chrome’s rendering engine and below is a quick description of the flow that is followed for rendering.
- HTML Parser → Parses an HTML document, converts elements to nodes and creates a DOM Tree.
- CSS Parser → Parses the style sheets and creates style rules.
- The style rules are attached to the DOM Tree to create a Render Tree.
- The render tree then goes through the layout process where each node in the tree is assigned a position coordinate for the screen display.
- Finally, the rendering engine will traverse through each node in the render tree and paints those nodes using the UI backend. Paint() is a method which is called while traversing the render tree and displaying the content on the screen.
The painting order is as follows:
background-color → background image → border → children → outline
Note: Browsers run multiple instances of the rendering engine - one instance for each tab. Each tab in a browser runs in a separate process.
Networking
It is used for making network calls, like Hyper Text Transfer Protocol (HTTP) requests to the server and also handles security for these calls. The web browser communicates with web servers using HTTP. When you click any link on a web page or run a search, it sends an HTTP Request to the server.
JavaScript Engine
JavaScript engine is used to parse and execute the JavaScript code.
Every browser has a JavaScript engine which handles how the end users interact with the graphical element. Different JavaScript engines are as follows :
- V8: Chrome
- Nitro: Safari
- Carakan: Opera
- Spider Monkey/Jager Monkey: Firefox
- Chakra: IE9
The JavaScript engine processes all the interactions of the user with the web page. It executes all the JavaScript code of the document and sends the results to the rendering engine.
UI Backend
It is used for drawing basic widgets like a select box, a check box, an input box etc.
Data Persistence
The browser may also need to save the data locally, such as cookies. The browser also supports storage mechanisms such as local storage (limit up to 5mb), Session Storage, Indexed Db, Web SQL and File Systems.
Conclusion
Hope this understanding of the browser will help you build robust applications that are performant, and more usable and take advantage of the ways different processes work internally in a browser.
Set up Zipy and start tracking browser errors:
- Visit https://app.zipy.ai/sign-up to get the project key.
- Install Zipy via script tag or npm. window.zipy.init() must be called client-side, not server-side.



.webp)